Easy word cloud with R — Peru’s presidential debate version
Peru has been in political crisis in the last months of 2020, due to this, the presidential election of 2021 were of greater importance for the general population.
I decided to show in a simple way the proposals launched by the candidates during the first presidential debate and share it through twitter. Using word cloud was an easy way to compare the candidates’ proposals.
Let’s start!
The easiest and fastest way to obtain the transcript of the debate was using YouTube annotations, these were generated after the live broadcast of the debate. Automatic captions generated by YouTube are not perfect, but as the debate is an exhibition without interruption the faults found are minimal.
Now we can use in .txt file the youtube annotations with the seconds marked. As the discussion blocks are segmented and there is a specific order for the presentation of each candidate, it is easy for us to do a manual separation of the transcription. As a result, we generate our database that is made up of each candidate and each debate segment.

Now, Let’s Code
The libraries that we will use for this project are:
- tidyverse, because there is no R project without this
- textmining — tm, to be able to do operations on the texts
- SnowballC, to remove stopwords in Spanish or English
- wordcloud2, to graph the word cloud, I can also use worldclud, but the first one shows a fancier graph.
library(tidyverse)
library(tm)# para el text mining
library(SnowballC) # para quitar las stopwords
library(wordcloud2) #wordcloud con mejores interaccionesReading the .txt file with readLines and use UTF-8 encoding because the debate is in Spanish and it generated words with special characters
x = readLines("debate/vm_corrupcion.txt", encoding="UTF-8")The loaded files have the following form:
[1] "a diferencia de algunos candidatos aquí" "09:08"
[3] "presentes que están siendo procesados" "09:10"
[5] "por haber recibido financiamiento turbio" "09:12"
[7] "en sus campañas electorales o por haber" "09:15"
Cleaning .txt files
Transform the vector into a list of lists corpus to make cleaning the text
x = Corpus(VectorSource(x))- Remove numbers, punctuation, spaces and symbols from the list
- Change the words to lowercase
- Remove the stopwords in Spanish
- Remove some words not considered in the stopword list
x = x %>%
tm_map(removeNumbers)%>% # eliminar los minutos
tm_map(removePunctuation)%>% # eliminar puntuacion
tm_map(stripWhitespace)%>% # quito dobles espacios
tm_map(content_transformer(tolower))%>% # aplicamos minusculas
tm_map(removeWords, stopwords("Spanish"))%>% # quito stopwords
tm_map(removeWords,
c("entonces","aquí","el",
"de","en","que",
"por","los","las","para",
"una","con","este"))# quito mis propias stopwords- Now that we clean up the text, it’s time to shape the base to make the graphics
- We create a table with the repetition frequency of each word, we transform it into a matrix and we obtain the following
dtm = TermDocumentMatrix(x)
matriz = as.matrix(dtm)
- Add the rows of the matrix to create a vector called palabras with the quantity and frequency of each word
palabras = sort(rowSums(matriz), decreasing = TRUE)
- Finally we create a dataframe with words and assign it a column with the name of the candidate
x_df = data.frame(
row.names = NULL,
palabra = names(palabras),
freq = palabras,
candidato = "iniciales")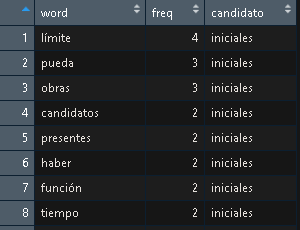
Now that we have the dataframe and the clean base, I’m going to join all the steps in a function that uses the .txt file and the initials of the candidate called iniciales, I am calling this function nube
nube = function(x,iniciales){
x = Corpus(VectorSource(vm))
x = x %>%
tm_map(removeNumbers)%>%
tm_map(removePunctuation)%>%
tm_map(stripWhitespace)%>%
tm_map(content_transformer(tolower))%>%
tm_map(removeWords, stopwords("Spanish"))%>%
tm_map(removeWords,
c("entonces","aquí","el","de","en","que",
"por","los","las","para","una","con","este"))
dtm = TermDocumentMatrix(x)
matriz = as.matrix(dtm)
palabras = sort(rowSums(matriz), decreasing = TRUE)
x_df = data.frame(
row.names = NULL,
palabra = names(palabras),
freq = palabras,
candidato = iniciales)
return(x_df)
}Creating a word cloud
Now that we have the dataframe we can create the word cloud, we just need to load the .txt file, clean the data with the cloud function and graph the word cloud.
- Use the data frame with the column of words and frequency of words, size defines the size of the words, use ‘random-cark’ for the text colors (or also use ‘random-light’)
vm = readLines("debate/vm_pandemia.txt", encoding = "UTF-8") df_vm = nube(vm,"VM")wordcloud2(data = df_vm[1:2], size = 0.8, color = 'random-dark')
And voila, our word cloud is generated

We can make a comparison between the word cloud of the candidates by proposed topic, this can give us an idea of the proposal of each candidate.
You can see the comparison made by the different topics and candidates on my Rpubs page, at this link.
I leave the complete code of my git page here
